
En permanence, l’entreprise se pose la question d’optimiser ses budgets afin de tirer le meilleur parti de l’année en cours tout en préservant ses capacités à préparer l’avenir. Les économies de coûts portent tout à la fois sur les opérations quotidiennes, dont on attend que leur productivité s’améliore, et sur le scope des projets identifiés, documentés, solides en promesse de ROI mais dont on sait dès le départ qu’il sera impossible de les financer tous.
Le DSI connait bien ces problématiques :
- l’entreprise le sollicite pour tous ses projets de transformation, qu’ils soient orientés vers le marché et le client ou qu’ils visent à améliorer l’efficacité des organisations internes ;
- il lui est aussi demandé de contribuer à maintenir l’entreprise en règle vis-à-vis des obligations réglementaires, en fournissant les informations requises par les administrations ;
- enfin, il pilote un ensemble de projets techniques, « IT sur IT », qui doivent lui permettre d’être plus efficace (déploiement de l’agilité, mise en place de DevOps) ou de sécuriser de nouveaux paliers techniques (cybersécurité par exemple).
Pourtant l’essentiel de son budget est consacré au maintien des activités du quotidien (« Run ») et non aux projets (« Build ») :
« Le Run représente 70 % de notre budget et 10 % de notre attention managériale » Paul Thysens, ex DSI de BNL et Fortis BNP Paribas
Il serait temps de travailler ces ratios. Non pas par esprit de logique mais plutôt par pragmatisme. En effet : si 5 % du budget de l’informatique pouvait glisser du Run vers les projets, ceux-ci passeraient de 30 à 35 %, ce qui représente une augmentation de 17 %.
Une rapide exploration sur internet fait émerger un ensemble d’offres pour réduire le coût du support : mieux s’outiller (« avez-vous pensé au workflow ? »), délocaliser (« imaginez les économies réalisées si vous mettiez votre support ici ou là »), mettre un bot.
Le lean management propose une autre voie. Il contient un large volet de maintien en condition opérationnelle des machines industrielles, le plus souvent connu sous le nom de « Total Productive Maintenance ». Par analogie, nous nous sommes posés la question de savoir si et comment cette démarche TPM pouvait s’appliquer au monde informatique. Obtenir des installations techniques et des applications de plus en plus fiables permettrait d’apporter trois améliorations concrètes :
- offrir une meilleure expérience digitale aux clients et aux salariés ;
- réduire les budgets de support de façon visible ;
- rendre disponibles des collaborateurs compétents, qui pourraient rapidement rejoindre les projets.
Nous nous sommes posés cette question il y a 15 ans et aujourd’hui nous avons accumulé plus d’une centaine de déploiements du lean dans les domaines du support informatique, la plupart au sein de DSI, d’autres chez des éditeurs ou des ESN.
Voici notre état de l’art.
Délai et productivité
Nous appelons ce domaine d’application du lean « Accélérer » (resolvebyOP). Dans le monde DevOps, on parle de l’indicateur « Time to restore ».
Les délais de résolution des tickets sont fréquemment divisés par un ratio allant de 3 à 6 (on ne parle pas de l’épaisseur du trait !) et la productivité s’améliore à minima de 30 %.
Pour y parvenir, la méthode est très rodée : il s’agit d’appliquer le principe de « flux tiré » au cœur du lean, mais de l’appliquer avec beaucoup de rigueur.
Le Flux Tiré en quelques mots :
L’équipe construit son management visuel, l’alimente avec les tickets reçus et se fixe un objectif quotidien de clôture de ces tickets. Le point du matin sert à choisir la meilleure organisation pour parvenir à atteindre l’objectif.
Au fil du temps, différents obstacles vont émerger. L’un n’aura pas l’accès au serveur, l’autre attendra la réponse d’un tiers, etc… Tous ces obstacles vont alimenter la réflexion de l’équipe afin de trouver comment les éliminer.
En deux mois, les résultats sont là. Les équipes les plus agressives sur la réduction des délais entament alors une deuxième amélioration : rapatrier le traitement de certains incidents des niveaux 2 et 3 (les plus experts) vers le niveau 1 (le 1er intervenant, plus généraliste) avec comme bénéfice une vitesse plus grande de traitement et une réduction du coût du ticket.
Le ROI d’une démarche lean dans ce domaine est de quelques mois.
Excellent témoignage d’Alexandre Nouchet, Leroy Merlin ici :
Fiabilité
Il s’agit du 2e étage de la fusée : la rapidité du traitement des tickets est déjà assurée et l’entreprise cherche maintenant à réduire le nombre des tickets en entrée. Par exemple, passer de 600 à 450 tickets sur un mois.
Pour le client ou l’utilisateur, c’est idéal car il est mieux servi. Pour l’entreprise, il s’agit d’une double opportunité de réduction des coûts :
- au niveau du Service Client, qui accueille les clients notamment lorsque les systèmes ne fonctionnent pas comme ils s’y attendaient ;
- au niveau des Help Desk, lorsque le Service Client ou les utilisateurs les sollicitent pour apporter une réponse technique aux difficultés rencontrées.
Avez-vous déjà essayé d’aborder avec des ingénieurs informaticiens l’idée de réduire le volume de tickets de support ? Le 1er réflexe est souvent de proposer aux utilisateurs une aide en ligne qui évitera de solliciter les équipes informatiques. L’esprit lean, ce n’est pas cela. Nous tous, en tant qu’utilisateurs des systèmes numériques, nous voulons surtout que les systèmes marchent, et non avoir une façon de nous en sortir tout seuls lorsqu’ils dysfonctionnent ou n’apportent pas une réponse pertinente.
Le second réflexe est alors d’expliquer que tous les incidents sont différents et qu’il n’y a aucune chance de les supprimer. D’ailleurs, l’entreprise s’est dotée de la méthodologie Itil qui prouve que chacun fait de son mieux.
Et pourtant…
Deux exercices lean peuvent faire accepter l’idée que la réduction des tickets est à portée de main :
Le Hoshin ou alignement stratégique : il s’agit ici d’accepter, aussi simple ou difficile que cela paraisse, l’ambition de réduire les volumes. Halte aux excuses, aux regrets, aux idées du passé, etc… On reprend le sujet comme on reprendrait un Rubik’s Cube qui vient d’être mélangé : en se demandant par où on va commercer.
Le Gemba : c’est d’ailleurs là que l’on va commencer. Il s’agit d’aller sur le terrain, voir de vraies pièces et de vrais processus. En effet, nous avons tous une vision ré-interprétée de la réalité qui va nous empêcher d’agir avec simplicité. En lisant le titre des 100 derniers tickets, différentes catégories actionnables vont apparaitre. Le gemba va aussi permettre de suivre l’incident de son évènement initial jusqu’à son impact visible par l’utilisateur.
Ces catégories issues du gemba et de la ferme détermination à réduire les tickets, issue du hoshin, vont permettre aux équipes en charge de tel ou tel système de trouver les origines de ces problèmes.
Je me souviens d’un help desk dont près de 60 % des appels avaient pour origine la demande d’un nouveau mot de passe. Après avoir testé le processus, les informaticiens avaient découvert … qu’il fallait être identifié dans le système pour demander ce mot de passe.
Ou de cet outil de reporting qui n’était bien alimenté que quelques jours par semaine. Une réflexion sur la nature des données à aller chercher (tous les contrats de tous les clients ou seulement les nouveaux contrats de la veille ?) a permis d’alléger les requêtes et de fiabiliser le reporting.
Ou de cette recherche de certificat qui ne fonctionnait qu’une fois sur deux. Eh oui, il y avait deux bases distinctes au bout de la requête ; l’une mise à jour avec les nouveaux certificats et l’autre qui aurait dû en être la copie mais dont le clonage de fonctionnait pas.
Une fois l’origine trouvée, l’action à mettre en œuvre est le plus souvent simple à identifier.
Obtenir une baisse de 20 % de ses tickets en 6 mois est non seulement envisageable, mais réaliste.
Budget du support avant et après lean
Pour cette estimation budgétaire, reprenons les chiffres présentés ci-dessus.
L’approche « délai et productivité » permet une augmentation de 30% a minima de la productivité et « fiabilité » une réduction des volumes de 20%. Quel est l’impact possible sur le budget du support ?
Sur une base initiale de budget de 100, voici comment se calcule un budget théorique :
100 x 70% (gain de productivité) x 80% (amélioration de la fiabilité),
soit 56 versus 100
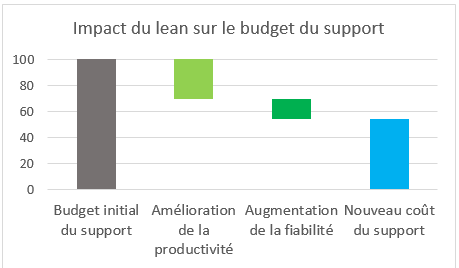
Dans la pratique, il peut y avoir des effets de seuil, des questions sur le repositionnement des équipes, etc… La réduction de budget réel est à caler par chaque entreprise.
De nouvelles opportunités
Au fil des années, certains de nos clients ont innové autour des approches « délai et productivité » / « fiabilité ». Voici deux exemples.
1.Incidents et big data
Le traitement de données de masse couplé à une démarche lean permet d’aller plus loin dans l’amélioration des incidents.
L’un de nos clients, responsable des flux financiers d’une banque (virements, instant payments, cartes bancaires, etc…), a ainsi installé un système très fin de supervision de ses flux en temps réel pour identifier au vol les situations anormales. Cela lui a permis de réduire encore les délais de réparation des incidents. Cet outil n’avait pas d’incidence sur la productivité des équipes ou le volume global de tickets ; il en a fait un complément de sa politique lean.
Témoignage ici de Kenneth Trickett, BNP Paribas :
Autre exemple, innovant. Le responsable d’un parc d’infrastructures, une fois avoir mis la situation sous contrôle avec les deux premières étapes lean, a identifié des facteurs de fragilité répétitif. Il a construit un « score d’obsolescence » prédictif des incidents puis construit un planning de maintenance préventive pour mettre son parc d’environnement au bon niveau, avant que les incidents n’apparaissent. Le taux de disponibilité de ce parc a évolué de 98,+ à 99,+.
2.Equipe « produit »
Chaque démarche lean sur le support et les incidents se traduit par un regret : « il faudrait maintenant s’attaquer aux changes ! ». En effet, la qualité de mise en production des changes se traduit souvent par un pic de tickets.
L’équipe « produit » porte une promesse d’amélioration dans ce domaine. En charge à la fois du « run » et du « change » de son périmètre, elle peut bénéficier d’une boucle de rétroaction très rapide entre l’analyse des incidents et les pratiques de développement. Peu d’équipes le mettent vraiment en pratique. Le concept est simple à comprendre mais son application demande du temps, donc du soutien managérial explicite, et de la méthode.
Un éditeur de logiciel y est parvenu. Ses clients, des grands comptes, ne souhaitaient plus investir dans les nouvelles versions proposées. Ses commerciaux remontaient de grandes insatisfactions sur la qualité livrée. Encouragés par leurs dirigeants, les équipes ont accepté de revoir leurs procédures de tests techniques et fonctionnels pour améliorer la qualité des releases livrées.
Rapidement, les clients ont accepté de migrer vers les versions les plus récentes du produit, ce qui a eu un impact positif sur le chiffre d’affaires et un impact inattendu sur le support qui a pu se libérer des questions de régression avec les versions plus anciennes.
En conclusion
Il est plus vertueux d’aller optimiser son support pour financer de nouveaux projets que d’aller voir son DAF ou son banquier !
J’ai présenté dans cet article des pistes d’optimisation solides avec de vrais impacts sur les budgets. Le succès demande de réunir trois conditions :
Un manager déterminé car le succès vient des équipes. Elles sont toujours légitimistes, au sens où elles acceptent volontiers de travailler sur les axes que leur soumet leur management.
Un coach avec une triple expertise :
- en conduite du changement, car à nouveau le succès viendra des équipes ;
- en lean avec une excellente maitrise du flux tiré et de la TPM (Total Productive Maintenance), pour fournir aux acteurs le cadre pertinent de réflexion ;
- en informatique (développement, opérations, data, etc…), pour générer de la confiance entre les collaborateurs du support et lui.
Un esprit d’aventure collective car il s’agit bien de challenger le statu quo, les processus établis, les KPI non pertinents, les habitudes ancrées de recherche de responsabilité pour entrer dans un nouveau mode de fonctionnement dans lequel chacun peut réfléchir, expérimenter, innover pour le bénéfice de l’entreprise, de ses clients et, in fine, de soi-même.
Pour en savoir plus, inscrivez-vous à l’un de nos rendez-vous du mardi de 12h à 12h30 pour découvrir Resolve, notre offre dédiée au support. Envoyez-nous un email : contact at operaepartners . com et nous vous enverrons un lien pour vous connecter à la session d’échange – démonstration.
