
Dix mois ont suffi pour mettre au point et fabriquer le vaccin contre la Covid-19 alors qu’au début de la crise sanitaire, les estimations annonçaient plutôt vingt mois de délais. Cette rapidité de développement laisse songeuses certaines équipes informatiques s’échinant à concevoir et livrer leur nouveau produit. Les projets informatiques ont aussi leur lot de crises après des séries de plans d’urgence en retard.
Comment le Lean IT peut-il aider les équipes IT à surmonter une crise client ou interne ?
Pour l’illustrer, prenons l’exemple vécu chez un éditeur de solutions informatiques, se lançant dans la création d’une nouvelle solution de paiement mobile en janvier 2020 pour concurrencer de nouveaux entrants chinois sur leurs marchés historiques européens et américains. L’ambition était de le mettre en vente dès juin 2020. Un an et deux réorganisations plus tard, en janvier 2021, le produit n’est toujours pas commercialisé, pas même en test chez un client pilote. Après avoir subi 15 décalages successifs sur 20 jalons, la Direction Générale tape du poing et impose de le livrer en 2,5 mois soit le 4 avril. L’enjeu est de conserver la position dominante sur ses marchés et de rester durablement compétitif.
Dans cette situation trouble, un manager est nommé 18 jours avant le démarrage du produit chez le client pour redresser ce projet en crise. A 9000 km des dévelopeurs et du chef de projet dont il est le N+4, il se doit de lever un à un les obstacles empêchant la livraison.
1. Comprendre ensemble tous les jours les pain points bloquant la livraison produit
Plutôt que de sauter instantanément du problème à la solution, comme le font souvent les personnes prises par le temps et sans réelle méthode de résolution de problème, le manager rompu à la démarche LEAN IT, se pose pour faire l’effort de comprendre et d’analyser en détail les problèmes. Son rôle maintenant, est d’aller de découvertes en découvertes en comprenant les raisons profondes.
Grâce aux mesures quotidiennes, il réalise lors d’une première réunion de 2 heures que les 15 développeurs sont complètement dépassés par :
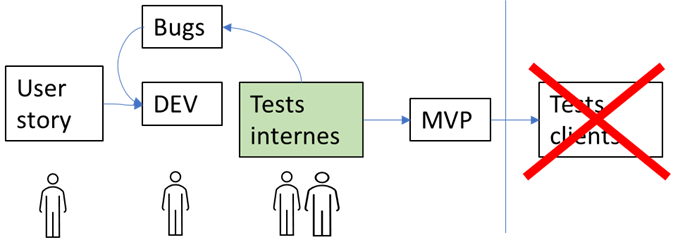
1.1) Les 121 bugs restant à corriger remontés par deux équipes distantes :
- d’une part , les équipes de recetteurs du centre de service externalisé : 66 bugs
- d’autre part, l’experte Acceptance en lien avec le client final : 55 bugs
1.2) Le volume de User Stories restant à produire : 74 user stories
Pour complexifier la situation, 10 nouveaux bugs en moyenne sont déclarés par jour alors que 6 bugs sont corrigés par jour.
Le manager constate d’abord que les équipes de recette distantes ne connaissent pas exactement les cas de test à réussir pour la MVP client (Minimal Valuable Product) et crée chaque jour de nouveaux cas de test, non communiqués aux developpeurs. De nouveaux bugs sont ainsi créés en dehors du périmètre requis par le client. Une clarification sur la valeur attendue s’impose.
Quelles sont les conditions précises de succès ? Comment chacune des équipes (distantes et colocalisées) reste-t-elle complètement alignée et, tous les jours sur les objectifs communs? Existe-il des actions inutiles à chaque étape du processus de création du produit qui ne répondent pas à la demande du client ?
2. Une collaboration globale et quotidienne pour gagner du temps
Deux des principaux rôles du manager (Lean) sont d’orienter et d’aider l’équipe à atteindre ses objectifs.
Sont-elles constamment alignées sur un même objectif limpide pour chacun ?
Un bon management visuel participe à l’intensification de la collaboration et d’autant plus lorsque les équipes sont distantes. En période de crise, l’équipe n’a pas le luxe de rater une journée de travail. Chaque matin, elle consacre 2 heures pour comprendre et voir ensemble la situation avant de se réunir 30 mn avec les représentants du client.
Avez-vous précisément compris ce qu’attend le client ? Les objectifs quotidiens sont-ils clairs ?
Collaborer avec le client et éliminer 57 % d’actions inutiles
Concrètement, que signifie s’aligner sur les véritables objectifs du client et sur un périmètre commun ?
- Le point de départ est de contacter le client tous les matins et de passer au moins 30 mn à s’aligner avec lui sur la qualité attendue pour la MVP. Les 532 cas de tests du client pour valider l’adéquation du produit sont donc partagés et répartis en 15 familles, 2 d’entre elles sont écartées car hors du périmètre. Cela permet de comprendre ce que le client veut réussir, de valider qu’il ne reste que 216 cas de tests à passer pour la MVP et non plus 728 cas dont une grande partie est hors périmètre. Dans ce cas, aller voir sur le « terrain » en informatique, signifie comprendre ce qui est réellement important pour le client et donc le détail et l’exhaustivité de ce qu’il attend plutôt que de naviguer de supputations en conjectures. Le Gemba « client » reste le point de départ de la gestion de crise.

- Une autre revue conjointe est aussi menée l’après-midi pour prioriser les bugs liés à ces cas de tests. Elle conduit à se concentrer en priorité sur 43 % des résolutions du stock de bugs. La valeur créée pour les utilisateurs se fabrique dans software factory. Un premier Gemba dans l’équipe de « DEV » révèle qu’elle ne livre pas les composants correspondant aux attentes.
- L’équipe apprend enfin du challenge client, connait 532 cas que va vérifier le client et sait sur quoi porter ses efforts.

A la fin de cette première journée, les objectifs sont partagés, le backlog est clarifié, la définition du DONE DONE et les contributions de chacun au succès sont éclaircies. Les jours suivants, le management visuel montre les premiers gaspillages :
- 8 résolutions en cours de DEV sur 16 sont encore en dehors du périmètre
- 2 correctifs ne fonctionnant pas du premier coup
- 3 nouveaux bugs sur 6 sont encore hors périmètre
Quelles sont les causes de ces ralentissements ?
Collaborer activement en interne et appareiller DEV et recetteurs
Après développement, 10 bugs par jour sont remontés par les recetteurs.
Pourquoi les QA testers se plaignent que les DEV ne comprennent pas les workflows transactionnels ? Pour éviter ces aller-retours récurrents entre QA tester et DEV, les testers et DEV se regroupent dans une même salle. Cela évite de s’envoyer des mails qui s’empilent dans les boites aux lettres… Dorénavant, pour chaque correction ou nouvelle fonctionnalité, le manager leur suggère que le DEV et le testeur correspondant effectuent l’un à côté de l’autre la recette. Les tests unitaires et d’intégration après Merge sont remplacés par ces tests conjoints. DEV comme testers font leur Genchi Genbutsu (= observer au plus près des problèmes, de la vérité du terrain et comprendre la situation). Ils réagissent ensemble sur le terrain pour résoudre les problèmes.
Les premiers effets sont vite observés, la couverture des tests réussis augmente en 10 jours de 26 % à 67 %. En réussissant ensemble tous les jours, les personnes ont recommencé à se faire mutuellement confiance.

Pourquoi ces problèmes existent ? Pourquoi certains bugs reviennent ? Quelles sont les causes profondes des temps de réponse de 1500 au lieu de 110 millisecondes ?
3. S’atteler à supprimer « à froid » les causes profondes des problèmes, l’une après l’autre
L’exécution du plan défini ne se passe pas complètement comme prévu. Des obstacles sont révélés tous les jours.
Quelles en sont les causes ?
Les boucles d’apprentissage de l’organisation développe le savoir faire des personnes en apprenant ce que l’on ne savait pas faire.
Un puis deux bugs de régression apparaissent.
Que se passe-t-il ?
Retournons sur le Gemba de la production informatique, dans l’outil de développement accompagné de DEV. Dans les deux cas, il apparait dans l’historique que 2 DEV différents ont travaillé sur le même bloc de code à 6 heures d’intervalle. Le dernier l’ayant modifié, a supprimé la ligne de code écrite par le précédent. Après un merge sur la branche Main, il s’est avéré que la suppression de cette ligne a généré la régression transactionnelle remontée par le testeur.

Pourquoi cette suppression a-elle été effectuée ?
La dernière personne ne comprenant pas l’utilité de cette ligne de code l’a simplement effacé.
Le standard de coding a été modifié pour rappeler les bonnes pratiques au DEV. Le DEV compare son code par rapport à la dernière modification de son bloc sur un programme et échange avec le dernier DEV l’ayant modifié avant toute suppression. Il ne décide plus de son propre chef de supprimer du code sans consulter préalablement son auteur et vérifie systématiquement le dernier historique des modifications.
Autre exemple, le temps de réponse d’une transaction sur le terminal est d’environ 1500 millisecondes, alors que le client souhaite attendre 110 millisecondes maximum. Le code montre qu’à chaque fois qu’un montant est saisi, une requête de téléchargement des fichiers de configuration est envoyée au server Host pour initialiser le terminal. Non seulement cela retarde l’exécution de près de 400 millisecondes à chaque requête mais cela ne répond pas à la demande client.
De plus, cela n’est pas bon pour notre planète. En effet, chaque requête vers le Host consomme de l’énergie électrique et augmente l’empreinte carbone à chaque exécution de ce morceau de code. Je suis d’autant plus sensible à ce dernier aspect de la performance Lean Green IT car il est malheureusement encore trop souvent négligé.
Pourquoi ce chargement est-il fait à chaque transaction ?
Le code fait appel à une Library qui effectue à chaque fois ce chargement.
Pourquoi cette library a-t-elle été conçue de cette façon ?
Cette library ne respecte pas la spécification correspondante. En effet, ce dernier document stipule bien de ne faire qu’un seul chargement initial. Il s’avère que les DEV pour la plupart ont moins de 6 mois d’ancienneté dans le groupe et n’ont pas été formés à ce chapitre de la spécification. Ils ne l’ont donc pas appliqué.
Un DEV senior s’occupe de programmer des sessions de formation avec chacun d’eux.
Pour atteindre l’objectif des 110 ms, d’autres modifications dans le code ont été effectuées comme l’annulation de la création de certains fichiers Log.
Le Gemba dans le code permet de déceler les écarts aux bonnes pratiques et d’accélérer l’apprentissage des DEV.

En conclusion, le Gemba factualise sur le terrain les difficultés rencontrées par les équipes opérationnelles. En période de crise, le manager doit prendre les bonnes décisions encore plus rapidement. Les découvertes faites quotidiennement sur le Gemba sont une aide précieuse pour orienter les équipes sur les bons sujets et la résolution continue des problèmes . Cela accélère les livraisons. Dans notre cas, l’équipe a livré « juste à temps » la solution en multipliant par 5 sa productivité. (Ironie du sort : le client pilote a essuyé deux semaines de retard en raison de l’indisponibilité d’une de ses équipes IT)…
NB : L’illustration de ce billet est une image extraite du film “Imitation Game” qui raconte comment Alan Turing et son équipe ont mis 11 mois pour mettre au point une machine capable de déchiffrer 18000 messages codés émanant de la marine allemande durant la seconde guerre mondiale.
Vous souhaitez être accompagnés ou connaître nos offres ? Contactez-nous avec le formulaire ci-dessous :



5 réflexions sur “Projet informatique critique en danger ? Allez sur le gemba !”